

K-Means算法为我们的数据分析之路带来的便利
来源:CPDA数据分析师网 / 作者:数据君 / 时间:2020-02-03
K-Means算法的原理:大致分为四个步骤
1、 步输入数据集:系统会初始化选择K个聚类中心,这里所说的K需要我们自己去给它进行定义
2、 第二部计算每个样本数据到质心的距离:计算完以后我们会选取距离近的类别作为这个样本的标记类别。
3、 第三部新的样本数据加入到这个类别,我们就要随之更新这个类别的中心点,也就是质心。
4、 第四部我们需要重复以上第二部、第三部的过程直到一下三个条件之一发生的时候算法终止。
那是哪三个条件发生的时候那,这里是算法的一个重点一定要牢记。
1、 直到没有聚类中心发生变化的时候
2、 重置的聚类中心与原聚类中心的距离小于我们之前设置好的某一个阈值。
3、 当算法次数达到迭代次数的时候算法终止。
以上三条完成其中一个算法就会终止。
数据分析Datahoop算法在平台中的详细实操演练
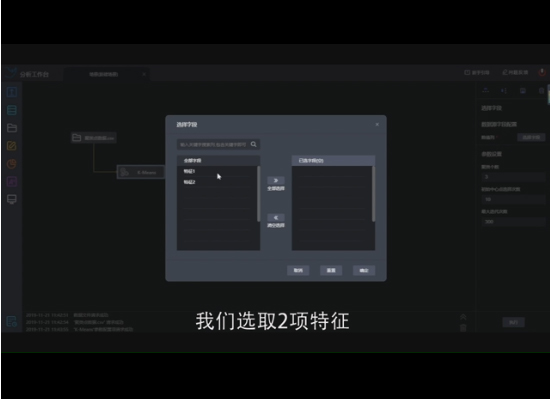
首先打开专业版分析工作台:拖拽出数据集模块进行选择,实例中选择一个聚类点的数据,该数据有两项特征分为特征1、特征2我们可以把它类比成直角坐标系下横纵坐标,特征1为横坐标特征2为纵坐标。
回到工作台拖拽K-Means算法与数据进行连接,数值列选取两项特征点击确定,聚类个数我们选择2,初始中心点我们选择10次并选择的一次作为模型的解,迭代次数设置成300,参数选择完成之后点击执行,执行操作成功后我们选择结果展示模块进行结果的接收,点击查看就可以看到通过模型指标1该模型的平均轮廓系数为0.44轮廓系数的取值从1到负1越靠近1模型的结果越好。
通过蔟内误方差图我们可以看到当K值等于2或等于4的时候方差图的曲线坡度较大因此我们的K值在2到4中选择。
通过聚类个数与轮廓系数图我们可以看到当K值等于2的时候其轮廓系数远小于K等于4的时候。
通过这个简单的示范,我们回到算法将聚类个数改为4其他算法不变点击执行,执行成功后查看结果我们可以看到平均轮廓系数由之前的0,4变为0.57同时它的样本个数也比较平均,当K值等于4的时候模型的轮廓系数是的,所以此时模型为模型。












